реклама
Вярвате ли в идеята, че след като нещо се публикува в интернет, то се публикува завинаги? Е, днес ще разсеем този мит.
Истината е, че в много случаи е напълно възможно да се изтрие информация от Интернет. Разбира се, има запис на уеб страници, които са били изтрити, ако търсите в Wayback машина, нали? Да, абсолютно. На Wayback Machine има записи на уеб страници, които се връщат много години назад - страници, които няма да намерите с търсене в Google, защото уеб страницата вече не съществува. Някой го е изтрил или уебсайтът е затворен.
Така че, няма да се заобиколи, нали? Информацията завинаги ще бъде врязана в камъка на Интернет, там за поколенията да видят? Е, не точно.
Истината е, че въпреки че може да е трудно или невъзможно да се заличат основните новинарски истории, които са се разпространили от един новинарски уебсайт или блог до друг като вирус, всъщност е доста лесно да изтриете напълно уеб страница или няколко уеб страници от всички записи на съществуване - да я премахнете както за двете търсачки, така и за на
Wayback машина Новата машина за връщане назад ви позволява визуално да пътувате обратно в интернет времеИзглежда, че след пускането на Wayback Machine през 2001 г., собствениците на сайтове са решили да изхвърлят базиран на Alexa бек-енд и да го препроектират със собствен код с отворен код. След провеждане на тестове с ... Прочетете още . Има улов разбира се, но ще стигнем до това.3 начина да премахнете страниците на блога от мрежата
Първият метод е този, който повечето собственици на уебсайтове използват, тъй като те не знаят по-добре - просто изтриване на уеб страници. Това може да се случи, защото сте разбрали, че имате дублирано съдържание на сайта си или защото имате страница, която не искате да се показва в резултатите от търсенето.
Просто изтрийте страницата
Проблемът с изцяло изтриването на страници от уебсайта ви е, че тъй като вече сте създали страницата в Net, има вероятност да има връзки от вашия собствен сайт, както и външни връзки от други сайтове към този конкретен страница. Когато го изтриете, Google веднага разпознава тази ваша страница като липсваща страница.
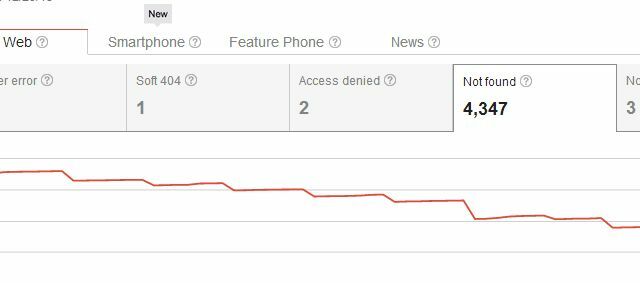
Така че, изтривайки страницата си, вие не само създадохте проблем с грешки при обхождане „Не е намерено“, но и създадохте проблем за всеки, който някога е свързал страницата. Обикновено потребителите, които стигнат до вашия сайт от една от тези външни връзки, ще видят вашата страница 404, което не е основен проблем, ако използвате нещо като персонализиран код на Google 404, за да дадете на потребителите полезни предложения или алтернативи. Но мислите, че може да има по-изящни начини за изтриване на страници от резултатите от търсенето, без да изритате всички тези 404 за съществуващите входящи връзки, нали?
Е, има.
Премахване на страница от резултатите от търсенето с Google
Първо, трябва да разберете, че ако уеб страницата, която искате да премахнете от резултатите от търсенето с Google, не е страница от вашия собствен сайт, тогава нямате късмет, освен ако няма правни причини или ако сайтът е публикувал личната ви информация онлайн без вашата разрешение. В такъв случай използвайте Google отстраняване на неизправности при отстраняване да изпратите заявка за премахване на страницата от резултатите от търсенето. Ако имате валиден случай, може да намерите успех с премахването на страницата - разбира се, че може да имате още по-голям успех свързване със собственика на уебсайта Как да премахнете невярна лична информация в ИнтернетОнлайн поверителността вече не е гарантирана. Научете как да подадете сигнал за уебсайт и да премахнете лична информация от интернет. Прочетете още както описах как да го направя през 2009 г.
Сега, ако страницата, която искате да премахнете от резултатите от търсенето, е на вашия собствен сайт, имате късмет. Всичко, което трябва да направите, е да създадете robots.txt файл и се уверете, че сте забранили или конкретната страница, която не искате в резултатите от търсенето, или цялата директория със съдържанието, което не искате да се индексира. Ето как изглежда блокирането на една страница
Потребителски агент: * Дезактивиране: /my-deleted-article-that-i-want-removed.html
Можете да блокирате ботовете да обхождат цели директории на вашия сайт, както следва.
Потребителски агент: * Дезактивиране: / съдържание-относно-лични неща /
Google има отличен страница за поддръжка което може да ви помогне да създадете файл robots.txt, ако никога не сте го създавали преди. Това работи изключително добре, както обясних наскоро в статия за структуриране на сделки за синдикация Как да преговаряте сделки за синдикация и да защитите вашите класирания за търсенеСиндикацията е цялата ярост в наши дни. Но изведнъж можете да откриете, че партньорът за синдикация е посочен по-високо от вас в резултатите от търсенето на история, която първоначално сте написали! Защитете своите класирания за търсене. Прочетете още за да не ви наранят (помолете партньорите за синдикация да забранят индексирането на техните страници, където сте обединени). След като моят собствен партньор за синдикация се съгласи да направи това, страниците, които бяха дублирано съдържание от моя блог, напълно изчезнаха от списъците за търсене.

Само основният уебсайт излезе на трето място за страницата, където те изброяват нашето заглавие, но моят блог вече е посочен както на първото, така и на второто място; нещо, което би било почти невъзможно, ако уебсайтът с по-висок орган остави дублираната страница индексирана.
Това, което много хора не осъзнават, е, че това е възможно да се постигне и с Интернет архива (Wayback Machine). Ето редовете, които трябва да добавите към файла си robots.txt, за да го направите.
Потребителски агент: ia_archiver. Дезактивиране: / примерна категория /
В този пример казвам на Интернет архива да премахне всичко от поддиректорията на примерната категория на моя сайт от Wayback Machine. Интернет архивът обяснява как да направите това на страницата им за помощ за изключване. Това е мястото, където те обясняват, че „Интернет архивът не се интересува от предлагане на достъп до уеб сайтове или други интернет документи, чиито автори не искат своите материали в колекцията.“
Това противоречи на общоприетото схващане, че всичко, публикувано в Интернет, ще бъде пометено в архива за цяла вечност. Nope - уеб администраторите, които притежават съдържанието, могат конкретно да премахнат съдържанието от архива, като използват подхода robots.txt.
Премахнете отделна страница с мета маркери
Ако имате само няколко отделни страници, които искате да премахнете от резултатите от търсенето с Google, всъщност не е нужно да използвате подхода robots.txt изобщо, можете просто да добавите правилния мета таг „robots“ към отделните страници и да кажете на роботите да не индексират или да следват връзки на всички страница.
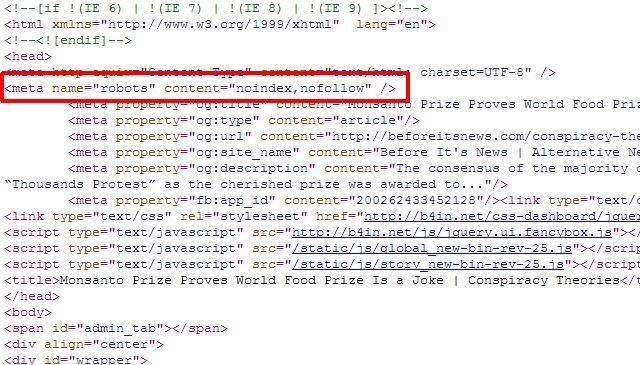
Можете да използвате мета „роботите“ по-горе, за да спрете роботите да индексират страницата, или можете конкретно да кажете на робота на Google да не се индексира, така че страницата да се премахва само от резултатите от търсенето с Google, а други роботи за търсене все още могат да получат достъп до нея съдържание.
От вас зависи изцяло как искате да управлявате какво правят роботите със страницата и дали страницата ще бъде изброена или не. Само за няколко отделни страници това може да е по-добрият подход. За да премахнете цяла директория със съдържание, преминете към метода robots.txt.
Идеята за „премахване“ на съдържание
Този вид завърта цялата представа за „изтриване на съдържание от интернет“ на главата му. Технически, ако премахнете всички свои собствени връзки към страница на вашия сайт и го премахнете от Google Търсене и Интернет архив, използващ техниката robots.txt, страницата е за всички намерения и цели „изтрита“ от Интернет. Хубавото обаче е, че ако има съществуващи връзки към страницата, тези връзки все още ще работят и няма да задействате 404 грешки за тези посетители.
Това е по-"нежният" подход за премахване на съдържание от интернет, без да се обърква изцяло съществуващата връзка на сайта Ви в интернет. В крайна сметка как ще управлявате какво съдържание се събира от търсачките и интернет архива зависи от вас, но винаги не забравяйте, че въпреки това, което хората казват за живота на нещата, които се публикуват онлайн, това наистина е напълно в рамките на вашия контрол.
Райън има бакалавърска степен по електротехника. Работил е 13 години в автоматизацията, 5 години е в ИТ, а сега е инженер на приложения. Бивш управляващ редактор на MakeUseOf, той говори на национални конференции за визуализация на данни и е участвал в националната телевизия и радио.

