реклама
През последните няколко месеца може би сте чели покритието около статия, в съавторство на Стивън Хокинг, обсъждайки рисковете, свързани с изкуствения интелект. Статията предполага, че AI може да представлява сериозен риск за човешката раса. Хокинг не е сам там - Елон Мъск и Питър Тиел и двете са интелектуални публични личности, които са изразили подобни притеснения (Тийл е инвестирал над 1,3 милиона долара в изследване на проблема и възможните решения).
Отразяването на статията на Хокинг и коментарите на Мъск бяха, за да не поставям твърде фина точка, малко весело. Тонът беше много "Виж това странно нещо, от което всички тези момчета се притесняват." Малко се обръща внимание на идеята, че ако някои от най-умните хора на Земята ви предупреждават, че нещо може да бъде много опасно, просто може да си струва да слушате.
Това е разбираемо - изкуственият интелект, превземащ света, със сигурност звучи много странно и неправдоподобна, може би заради огромното внимание, което вече е отделено на тази идея от научната фантастика писатели. И така, какво толкова се е уплашило всички тези номинално здрави, рационални хора?
Какво е интелигентност?
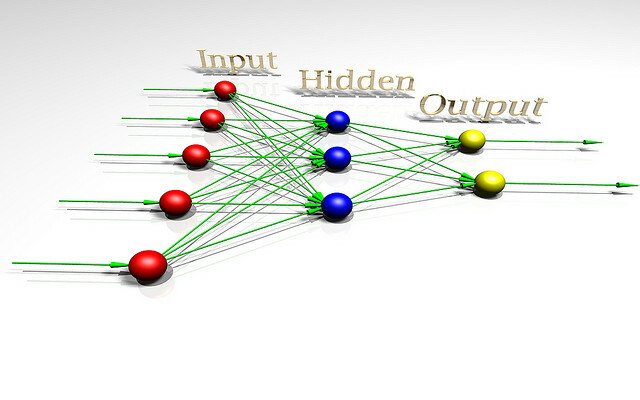
За да се говори за опасността от изкуствения интелект, може да е полезно да разберем какво е разузнаването. За да разберем по-добре проблема, нека разгледаме една играчка AI архитектура, използвана от изследователи, които изучават теорията на разсъжденията. Тази играчка AI се нарича AIXI и има редица полезни свойства. Целите му могат да бъдат произволни, той се отличава добре с изчислителната мощност, а вътрешният му дизайн е много чист и ясен.
Освен това можете да внедрите прости, практични версии на архитектурата, които могат да правят неща като играе Pacman, ако искаш. AIXI е продукт на AI изследовател на име Маркъс Хътър, може би най-добрият експерт по алгоритмична интелигентност. Това говори той във видеото по-горе.
AIXI е изненадващо прост: той има три основни компонента: учащ се, плановик, и полезна функция.
- Най- учащ се взема низове от битове, които съответстват на вход за външния свят, и търси чрез компютърни програми, докато не намери такива, които произвеждат наблюденията му като изход. Тези програми заедно му позволяват да гадае за това как ще изглежда бъдещето, просто като стартирате всяка Програмиране напред и претегляне на вероятността от резултата според продължителността на програмата (изпълнение на Occam's Razor).
- Най- плановик търси чрез възможни действия, които агентът може да предприеме, и използва модула за обучаване, за да предскаже какво би се случило, ако предприеме всяко от тях. След това ги оценява според това колко добри или лоши са прогнозните резултати и избира хода на действие, което максимизира добротата на очаквания резултат, умножено по очакваната вероятност от постигайки го.
- Последният модул, полезна функция, е проста програма, която включва описание на бъдещо състояние на света и изчислява полезен резултат за него. Този полезен резултат е колко добър или лош е този резултат и се използва от планиращия за оценка на бъдещото световно състояние. Функцията на полезността може да бъде произволна.
- Взети заедно, тези три компонента образуват оптимизатор, която оптимизира за определена цел, независимо от света, в който се намира.
Този прост модел представлява основно определение на интелигентен агент. Агентът изучава средата си, изгражда модели от нея и след това използва тези модели, за да намери хода на действието, който ще увеличи максимално шансовете за получаване на това, което иска. AIXI е подобна по структура на AI, който играе шах или други игри с известни правила - с изключение на това, че е в състояние да изведе правилата на играта, като я играе, като се започне от нулевото знание.
AIXI, имайки достатъчно време за изчисляване, може да се научи да оптимизира всяка система за всяка цел, колкото и сложна да е тя. Това е като цяло интелигентен алгоритъм. Обърнете внимание, че това не е същото като да имате човешки интелигентност (биологично вдъхновен ИИ е a съвсем различна тема Джовани Идили от OpenWorm: Мозъци, червеи и изкуствен интелектСимулирането на човешки мозък е много трудно, но проектът с отворен код предприема жизненоважни първи стъпки, като симулира неврологията и физиологията на едно от най-простите животни, познати на науката. Прочетете още ). С други думи, AIXI може да е в състояние да надхитри всяко човешко същество при каквато и да е интелектуална задача (имайки достатъчно изчислителна сила), но може би не осъзнава своята победа Мислещи машини: какво може да ни научи на съзнанието невронауката и изкуственият интелектМоже ли изграждането на изкуствено интелигентни машини и софтуер да ни научи за работата на съзнанието и същността на самия човешки ум? Прочетете още .

Като практически AI AIXI има много проблеми. Първо, няма начин да намери онези програми, които произвеждат продукцията, която се интересува. Това е алгоритъм на груба сила, което означава, че не е практично, ако не случайно имате произволно мощен компютър. Всяко реално прилагане на AIXI е по необходимост приблизително и (днес) като цяло е доста грубо. И все пак AIXI ни дава теоретичен поглед върху това как може да изглежда мощен изкуствен интелект и как може да причини.
Пространството на ценностите
ако сте направили всяко компютърно програмиране Основите на компютърното програмиране 101 - Променливи и типове данниСлед като се запознахме и поговорихме малко за обектно-ориентираното програмиране преди и къде е съименникът му идва от, реших, че е време да преминем през абсолютните основи на програмирането в неезиков специфичен начин. Това... Прочетете още , знаете, че компютрите са отвратително, педантично и механично буквални. Машината не знае или не я интересува какво искате да прави: тя прави само това, което му е казано. Това е важно понятие, когато говорим за машинен интелект.
Имайки това предвид, представете си, че сте измислили мощен изкуствен интелект - вие излезете с умни алгоритми за генериране на хипотези, които съответстват на вашите данни, и за генериране на добър кандидат планове. Вашият AI може да реши общи проблеми и може да го направи ефективно на съвременен компютърен хардуер.
Сега е време да изберете функция за полезност, която ще определи какви са AI стойностите. Какво трябва да го помолите да оцени? Не забравяйте, че машината ще бъде отвратително, педантично буквална за каквато функция да я поискате да увеличи и никога няма да спре - няма призрак в машината, която някога ще се „събуди“ и реши да промени функцията си на полезност, независимо от това колко подобрения на ефективността прави обосновавам се.
Елиезер Юдковски го кажете по този начин:
Както във всяко компютърно програмиране, основното предизвикателство и съществената трудност на AGI е, че ако напишем грешен код, AI няма автоматично да погледне кода ни, да маркира грешките, да разбере какво наистина искахме да кажем и да направи това вместо. Понякога непрограмистите си представят AGI или компютърните програми като аналог на служител, който следва поръчките безспорно. Но не е, че ИИ е абсолютно послушен към неговия код; по-скоро AI просто е кодът.
Ако се опитвате да работите с фабрика и кажете на машината да прави хартиени щипки и след това да я контролирате върху куп фабрични роботи, вие може да се върне на следващия ден, за да разбере, че е изчерпал всяка друга форма на суровина, уби всичките ви служители и направи хартиени щипки от техните останки. Ако в опит да поправите грешката си, вие препрограмирате машината, за да направи просто щастливи всички, може да се върнете на следващия ден, за да я намерите, като поставя кабели в мозъка на хората.

Въпросът тук е, че хората имат много сложни ценности, които предполагаме, че се споделят неявно с други умове. Ние ценим парите, но ценим човешкия живот повече. Искаме да бъдем щастливи, но не е задължително да влагаме жици в мозъка си, за да го направим. Не чувстваме нужда да изясняваме тези неща, когато даваме инструкции на други човешки същества. Не можете обаче да правите подобни предположения, когато проектирате функцията за полезност на машина. Най-добрите решения в рамките на бездушната математика на проста полезна функция често са решения, които човешките същества биха създали, тъй като са морално ужасяващи.
Разрешаването на интелигентна машина да увеличи функцията на наивната полезност почти винаги ще бъде катастрофално. Както казва философът от Оксфорд Ник Бостом,
Не можем да предположим, че свръх разузнаването непременно ще сподели някоя от крайните стойности, стереотипно свързана с мъдростта и интелектуалното развитие у хората - научно любопитство, доброжелателна грижа за другите, духовно просветление и съзерцание, отказ от материална придобивка, вкус към изисканата култура или към простите удоволствия в живота, смирение и безкористност и така нататък.
За да стане още по-лошо, много, много трудно е да се уточни пълният и подробен списък на всичко, което хората ценят. Въпросът има много аспекти и забравянето дори на един е потенциално катастрофално. Дори сред тези, които сме запознати, има тънкости и сложности, които затрудняват тяхното записване като чисти системи от уравнения, които можем да дадем на машина като функция на полезност.
Някои хора, като прочетат това, заключават, че изграждането на AI с полезни функции е ужасна идея и просто трябва да ги проектираме по различен начин. Тук има и лоши новини - формално можете да докажете това всеки агент, който няма нещо еквивалентно на функция на полезност, не може да има съгласувани предпочитания за бъдещето.
Рекурсивно самоусъвършенстване
Едно решение на горната дилема е да не се дава възможност на агентите на ИИ да нараняват хората: дайте им само необходимите ресурси решете проблема по начина, по който възнамерявате да бъде решен, контролирайте ги отблизо и ги дръжте далеч от възможностите да се справят чудесно вреда. За съжаление способността ни да контролираме интелигентните машини е силно подозрителна.
Дори и да не са много по-умни от нас, съществува възможността машината да се „зарежда“ - да събира по-добър хардуер или да подобрява собствения си код, което го прави още по-умен. Това би могло да позволи на машина да прескача човешкия разум с много порядки, като надхитри хората в същия смисъл, в който хората надхитрят котките. Този сценарий за първи път е предложен от човек на име I. J. Добрият, който работи по проекта за анализ на криптовалута Enigma с Алън Тюринг по време на Втората световна война. Той го нарече „разузнавателна експлозия“ и описа въпроса така:
Нека една ултраинтелигентна машина бъде определена като машина, която далеч може да надмине всички интелектуални дейности на всеки човек, колкото и да е умен. Тъй като проектирането на машини е една от тези интелектуални дейности, ултраинтелигентната машина може да проектира още по-добри машини; тогава безспорно ще има „разузнавателна експлозия“ и интелигентността на човека ще бъде оставена далеч назад. По този начин първата ултраинтелигентна машина е последното изобретение, което човек трябва да направи, при условие че машината е достатъчно послушна.
Не е гарантирано, че в нашата Вселена е възможна експлозия на разузнаването, но изглежда вероятно. С течение на времето компютрите получават по-бързи и основни сведения за изграждането на интелигентност. Това означава, че изискването за ресурс, за да направи последния скок до общо, усилващо разузнаване, спада и по-ниско. В един момент ще се озовем в свят, в който милиони хора могат да се качат на Best Buy и да вземат хардуера и техническа литература, от която се нуждаят за изграждане на самоусъвършенстващ се изкуствен интелект, който вече сме установили, може да бъде много опасно. Представете си свят, в който можете да правите атомни бомби от пръчки и скали. Това е бъдещето, което обсъждаме.
И ако една машина направи този скок, тя може много бързо да изпревари човешкия вид по отношение на интелектуалността производителност, решаване на проблеми, които милиард хора не могат да решат, по същия начин, по който хората могат да решават проблеми, които: a милиарди котки не могат
Той би могъл да разработи мощни роботи (или био или нанотехнологии) и сравнително бързо да придобие способността да прекроява света, както желае, и нямаше да можем да направим малко за него. Подобно разузнаване би могло да съблече Земята и останалата част от Слънчевата система за резервни части без много проблеми, на път да направи каквото му кажем. Изглежда вероятно подобно развитие да бъде катастрофално за човечеството. Изкуственият интелект не трябва да бъде злонамерен, за да унищожава света, просто катастрофално безразличен.
Както се казва: „Машината не ви обича или мрази, но вие сте направени от атоми, които може да използва за други неща.“
Оценка и смекчаване на риска
И така, ако приемем, че проектирането на мощен изкуствен интелект, който увеличава максимално простата полезна функция, е лошо, колко проблеми сме всъщност? Колко време имаме, преди да стане възможно да изградим такива видове машини? Разбира се, трудно е да се каже.
Разработчиците на изкуствен интелект са правя прогрес. 7 невероятни уебсайтове, за да видите най-новите програми за изкуствен интелектИзкуственият интелект все още не е HAL от 2001 г.: Космическата одисея…, но ние се приближаваме ужасно. Със сигурност, един ден може да е подобно на научнофантастичните тютюневи изделия, които биват избивани от Холивуд ... Прочетете още Машините, които изграждаме, и проблемите, които могат да решат, непрекъснато нарастват в обхвата си. През 1997 г. Deep Blue може да играе шах на ниво, по-голямо от човешки гросмайстор. През 2011 г. Уотсънът на IBM можеше да чете и синтезира достатъчно информация дълбоко и бързо, за да победи най-добрия човек играчи на отворен въпрос и отговор на играта, изпълнена с каламбури и игра на думи - това е голям напредък в четиринадесет години.
В момента Google е инвестирайте сериозно в изследване на задълбоченото обучение, техника, която позволява изграждането на мощни невронни мрежи чрез изграждане на вериги от по-прости невронни мрежи. Тази инвестиция му позволява да постигне сериозен напредък в разпознаването на реч и образ. Последната им придобивка в района е стартиране на Deep Learning, наречено DeepMind, за което са платили приблизително 400 милиона долара. Като част от условията на сделката, Google се съгласи да създаде етичен съвет, който да гарантира, че AI технологията им се развива безопасно.
В същото време IBM разработва Watson 2.0 и 3.0, системи, които са способни да обработват изображения и видео и да спорят за защита на заключенията. Те дадоха проста, ранна демонстрация на способността на Уотсън да синтезира аргументи за и против тема във видео демонстрацията по-долу. Резултатите са несъвършени, но впечатляваща стъпка независимо.
Никоя от тези технологии в момента не е опасна: изкуственият интелект като поле все още се бори да съвмести способностите, овладени от малки деца. Компютърното програмиране и AI дизайнът е много трудно, познавателно умение на високо ниво и вероятно ще бъде последната човешка задача, в която машините стават специалисти. Преди да стигнем до този момент, ще имаме и повсеместни машини които могат да карат Ето как ще стигнем до свят, изпълнен с автомобили без шофьориШофирането е досадна, опасна и взискателна задача. Възможно ли е един ден да бъде автоматизиран с технологията на автомобили на Google без шофьори? Прочетете още , практикува медицина и право, а вероятно и други неща с дълбоки икономически последици.
Времето, което ще ни отнеме да стигнем до инфлексната точка на самоусъвършенстване, просто зависи от това колко бързо имаме добри идеи. Прогнозите за технологичния напредък на тези видове са известни трудно. Не изглежда неразумно, че може да успеем да изградим силен ИИ след двадесет години, но също така не изглежда неразумно, че може да отнеме осемдесет години. Така или иначе това ще се случи в крайна сметка и има причина да вярваме, че когато това се случи, ще бъде изключително опасно.
И така, ако приемем, че това ще бъде проблем, какво можем да направим по въпроса? Отговорът е да се уверим, че първите интелигентни машини са безопасни, така че да могат да се зареждат до значително ниво на интелигентност и след това да ни предпазят от опасни машини, направени по-късно. Тази „безопасност“ се дефинира чрез споделяне на човешки ценности и готовност да защитават и помагат на човечеството.
Тъй като всъщност не можем да седнем и да програмираме човешки ценности в машината, вероятно ще е необходимо да проектираме полезна функция, която изисква машината да наблюдавайте хората, извеждайте нашите ценности и след това се опитвайте да ги увеличите максимално. За да се направи този процес на развитие безопасен, може да е полезно да се разработят и изкуствени интелекти, които са специално проектирани не да имаме предпочитания относно техните полезни функции, което ни позволява да ги коригираме или изключим без съпротива, ако започнат да се заблуждават по време на развитието.
Много от проблемите, които трябва да решим, за да изградим безопасна машинна интелигентност, са трудни математически, но има причина да вярваме, че те могат да бъдат решени. Редица различни организации работят по въпроса, включително Бъдещето на Института за хуманност в Оксфорд, и на Изследователски институт за машинно разузнаване (която Питър Тийл финансира).
MIRI се интересува конкретно от разработването на математиката, необходима за изграждане на приятелски AI. Ако се окаже, че изкуственият интелект за зареждане е възможен, тогава се развива този вид Първата технология на приятелски AI, ако успее, може да се превърне в най-важното нещо, което хората имат правен някога.
Мислите ли, че изкуственият интелект е опасен? Загрижени ли сте какво може да донесе бъдещето на AI? Споделете мислите си в секцията за коментари по-долу!
Кредити за изображения: Lwp Kommunikáció Via Flickr, “Невронна мрежа„, От fdecomite“, img_7801", От Стив дъждовна вода," E-Volve ", от Keoni Cabral,"new_20x", От Робърт Cudmore,"Кламери“, От Клифърд Уолъс
Писател и журналист със седалище в Югозапада, Андре гарантирано остава функционален до 50 градуса по Целзий и е водоустойчив до дълбочина от дванадесет фута.


