реклама
Уеб стъргалки автоматично събира информация и данни, които обикновено са достъпни само чрез посещение на уебсайт в браузър. Правейки това самостоятелно, скриптовете за изтриване на уеб отварят свят от възможности за извличане на данни, анализ на данни, статистически анализ и много други.
Защо уеб изстъргването е полезно
Ние живеем в ден и възраст, в които информацията е по-лесно достъпна от всеки друг път. Инфраструктурата, използвана за предаване на тези думи, които четете, е канал за повече знания, мнения и новини, отколкото някога е била достъпна за хората в историята на хората.
Толкова всъщност, че мозъкът на най-умния човек се повиши до 100% ефективност (някой трябва да направи филм за това), все още няма да може да държи 1/1000 от данните, съхранявани в интернет в Съединените щати сам.
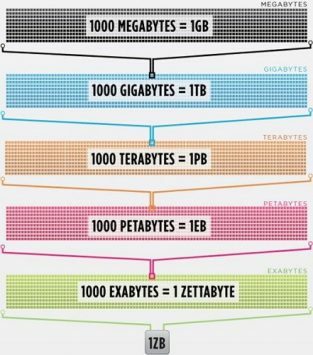
Cisco изчислена през 2016 г. че трафикът в интернет надвишава един zettabyte, който е 1 000 000 000 000 000 000 000 байта, или един байт секстилион (продължете напред, кикотете се при sextillion). Един zettabyte е около четири хиляди години поточно Netflix. Това би било равносилно на това, ако вие, безстрастният четец, ще предавате Службата от начало до край, без да спирате 500 000 пъти.
Всички тези данни и информация са много плашещи. Не всичко е точно. Не много от него е от значение за ежедневието, но все повече и повече устройства доставят тази информация от сървъри по целия свят право в очите ни и в мозъка ни.
Тъй като нашите очи и мозък не могат наистина да се справят с цялата тази информация, изтриването в мрежата се превърна в полезен метод за събиране на данни програмно от интернет. Изстъргването в мрежата е абстрактният термин за определяне на акта за извличане на данни от уебсайтове, за да се запази локално.
Помислете за тип данни и вероятно можете да ги събирате, като изстъргвате мрежата. Списък с недвижими имоти, спортни данни, имейл адреси на фирми от вашия район и дори текстовете от любимия ви изпълнител могат да бъдат търсени и запазени, като напишете малък сценарий.
Как браузърът получава уеб данни?
За да разберем уеб scrapers, ще трябва да разберем как работи мрежата първо. За да стигнете до този уебсайт, или сте въвели „makeuseof.com“ във вашия уеб браузър, или сте кликнали на връзка от друга уеб страница (кажете ни къде, сериозно искаме да знаем). Така или иначе следващите няколко стъпки са еднакви.
Първо, браузърът ви ще вземе URL адреса, който сте въвели или щракнали (Pro-tip: задръжте курсора на мишката над връзката, за да видите URL адреса на в долната част на браузъра си, преди да щракнете върху него, за да избегнете получаване на пънк) и образувайте „заявка“, която да изпратите до сървър. След това сървърът ще обработи заявката и ще изпрати отговор обратно.
Отговорът на сървъра съдържа HTML, JavaScript, CSS, JSON и други данни, необходими, за да може уеб браузърът ви да формира уеб страница за ваше удоволствие от гледане.
Проверка на уеб елементи
Съвременните браузъри ни позволяват някои подробности относно този процес. В Google Chrome на Windows можете да натиснете Ctrl + Shift + I или щракнете с десния бутон и изберете Огледайте. След това прозорецът ще представи екран, който изглежда по следния начин.

Списък с раздели с опции редове в горната част на прозореца. В момента интересното е мрежа раздел. Това ще даде подробности за HTTP трафика, както е показано по-долу.

В долния десен ъгъл виждаме информация за HTTP заявката. URL адресът е това, което очакваме, а „методът“ е HTTP „GET“ заявка. Кодът на състоянието от отговора е посочен като 200, което означава, че сървърът е видял заявката като валидна.
Под кода на състоянието се намира отдалеченият адрес, който е публично изправен IP адрес на сървъра makeuseof.com. Клиентът получава този адрес чрез DNS протокол Как да промените настройките на DNS, за да увеличите скоросттаПромяната на настройките ви за DNS е незначително изменение, което може да окаже голямо влияние върху ежедневните скорости на интернет. Ето как да го направите. Прочетете още .
Следващият раздел изброява подробности за отговора. Заглавката на отговора съдържа не само кода на състоянието, но и вида на данните или съдържанието, което отговорът съдържа. В този случай ние разглеждаме „text / html“ със стандартно кодиране. Това ни казва, че отговорът е буквално HTML код за визуализация на уебсайта.

Други видове отговори
Освен това сървърите могат да връщат обекти на данни като отговор на GET заявка, а не само HTML за уеб страницата за изобразяване. Сайт на уебсайт Интерфейс за програмиране на приложения (или API) Какво представляват API и как отворените API променят интернетЗамисляли ли сте се как програмите на вашия компютър и уебсайтовете, които посещавате, си говорят помежду си? Прочетете още обикновено използва този тип обмен.
Проверявайки раздела Мрежа, както е показано по-горе, можете да видите дали има такъв тип размяна. При разследване на CrossFit Open Leaderboard показва се искането за попълване на таблицата с данни.
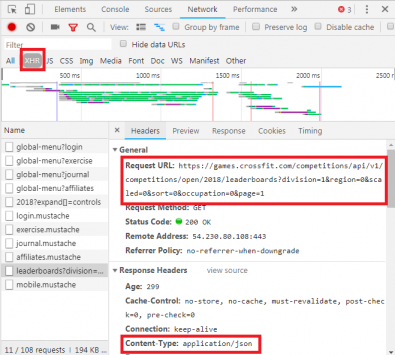
С кликване върху отговора се показват данните на JSON вместо HTML кода за изобразяване на уебсайта. Данните в JSON са поредица от етикети и стойности в многопластов, очертан списък.

Ръчното анализиране на HTML код или преминаване през хиляди двойки ключ / стойност на JSON е много като четене на матрицата. На пръв поглед изглежда като трептене. Възможно е да има твърде много информация, за да я декодирате ръчно.
Уеб Скрепери към спасителното!
Сега, преди да тръгнете да питате синьото хапче, за да извадим дяволите оттук, трябва да знаете, че не е необходимо ръчно да декодираме HTML код! Невежеството не е блаженство и това пържола е много вкусен.
Уеб скрепер може да изпълни тези трудни за вас задачи API на Scrapestack улеснява изтриването на уебсайтове за данниТърсите мощен и достъпен уеб скрепер? API на scrapestack е свободен за стартиране и предлага много удобни инструменти. Прочетете още . Рамките за остъргване са достъпни на Python, JavaScript, Node и други езици. Един от най-лесните начини да започнете изстъргването е с помощта на Python и Beautiful Soup.
Изстъргване на уебсайт с Python
Първите стъпки отнемат само няколко реда код, стига да сте инсталирани Python и BeautifulSoup. Ето малък скрипт, за да получите източник на уебсайт и да оставите BeautifulSoup да го оцени.
от bs4 import BeautifulSoup. искания за импортиране url = " http://www.athleticvolume.com/programming/" content = questions.get (URL) супа = BeautifulSoup (content.text) печат (супа)Много просто, ние отправяме GET заявка към URL и след това поставяме отговора в обект. При отпечатване на обекта се показва HTML код на URL адреса. Процесът е точно така, сякаш ръчно отидохме на уебсайта и щракнахме Виж източника.
По-конкретно, това е уебсайт, който публикува тренировки в стил CrossFit всеки ден, но само по един на ден. Можем да изградим нашия скрепер, за да получим тренировката всеки ден, след което да го добавим към обобщаващ списък от тренировки. По същество можем да създадем текстово базирана историческа база данни за тренировки, през които лесно можем да търсим.
Магията на BeaufiulSoup е възможността да търсите през целия HTML код, използвайки вградената функция findAll (). В този конкретен случай уебсайтът използва няколко маркера „sqs-block-content“. Следователно сценарият трябва да прегледа всички тези тагове и да намери този, който ни е интересен.
Освен това има редица
тагове в секцията. Скриптът може да добави целия текст от всеки от тези маркери към локална променлива. За да направите това, добавете обикновен цикъл към скрипта:
за div_class в супа.findAll ('div', {'class': 'sqs-block-content'}): recordThis = Грешно за p в div_class.findAll ('p'): ако 'PROGRAM' в p.text.upper (): recordThis = Вярно, ако recordThis: program + = p.text програма + = '\ n'
Готово! Ражда се уеб скрепер.
Разширяване на изстъргване
Две пътеки съществуват, за да продължат напред.
Един от начините за изследване на мрежовото изстъргване е използването на вече изградени инструменти. Уеб Скрепер (голямо име!) има 200 000 потребители и е лесен за използване. Също, Център за разбор позволява на потребителите да експортират изтрити данни в Excel и Google Sheets.
Освен това, Web Scraper предоставя a Приставка за Chrome което помага да се визуализира как е изграден уебсайт. Най-доброто от всичко, ако се съди по име, е OctoParse, мощен скрепер с интуитивен интерфейс.
И накрая, сега, когато знаете предисторията на изстъргването в мрежата, повишаване на собствения си малък уеб скрепер, за да можете пълзи и бяга Как да изградим основен уеб браузър за изтегляне на информация от уебсайтИскали ли сте някога да заснемате информация от уебсайт? Ето как да напишете робот, за да навигирате в уебсайт и да извлечете това, от което се нуждаете. Прочетете още само по себе си е забавно начинание.
Том е софтуерен инженер от Флорида (вика на Флорида Ман) със страст към писането, колежа футбол (отидете Gators!), CrossFit и Оксфорд запетайки.